Datadog es una plataforma de monitoreo y análisis de datos que se utiliza principalmente para observar infraestructuras de TI, aplicaciones y servicios en la nube. A continuación te detallo los principales usos de Datadog:
✅ 1. Monitoreo de Infraestructura
- Supervisa servidores, bases de datos, contenedores (como Docker), y servicios en la nube (AWS, Azure, GCP).
- Proporciona métricas en tiempo real (CPU, memoria, disco, red, etc.).
- Permite visualizar la salud de los sistemas desde un solo lugar.
✅ 2. Monitoreo de Aplicaciones (APM)
- Rastrear el rendimiento de aplicaciones (tiempos de respuesta, errores, cuellos de botella).
- Permite hacer trazabilidad completa de las peticiones (tracing).
- Compatible con muchos lenguajes (Java, Python, Node.js, Ruby, etc.).
✅ 3. Logs Management
- Recoge, centraliza y analiza logs de diferentes fuentes.
- Permite búsquedas avanzadas, alertas y correlaciones con métricas y trazas.
- Útil para auditoría, troubleshooting y análisis forense.
✅ 4. Monitoreo de Contenedores y Kubernetes
- Detecta automáticamente contenedores en ejecución.
- Monitorea el estado de clústeres Kubernetes.
- Visualiza el rendimiento y uso de recursos por pod, nodo y namespace.
✅ 5. Seguridad (Cloud Security Monitoring)
- Detecta amenazas y vulnerabilidades en tiempo real.
- Revisa configuraciones inseguras en la infraestructura.
- Integra seguridad con observabilidad para mejorar la respuesta a incidentes.
✅ 6. Dashboarding y Visualización
- Crea dashboards personalizados con métricas, logs y trazas.
- Widgets interactivos para ver el estado general o detalles específicos.
✅ 7. Alertas y Notificaciones
- Configura alertas basadas en métricas, logs, eventos o condiciones personalizadas.
- Integración con Slack, PagerDuty, email, etc.
- Soporta alertas predictivas basadas en machine learning.
✅ 8. Integraciones
- Tiene más de 600 integraciones listas (AWS, Azure, GCP, Docker, Jenkins, PostgreSQL, Redis, etc.).
- Fácil de conectar con otras herramientas de desarrollo, operación y seguridad.
Cómo relacionar jobs de Control‑M con métricas de infraestructura usando Datadog
En entornos empresariales donde conviven flujos batch complejos con microservicios, bases de datos y sistemas distribuidos, los errores no siempre vienen de fallos en la lógica del proceso. Muchas veces, la infraestructura subyacente es la responsable. En este artículo te muestro cómo integrar Control‑M con Datadog para ganar visibilidad completa y correlacionar fallos o lentitud en procesos con el estado real de tu infraestructura.
🎯 Objetivo
Enviar eventos desde Control‑M a Datadog en cada ejecución de job (exitoso o fallido), para poder:
- Ver el contexto exacto del job junto con métricas de CPU, RAM, disco, etc.
- Identificar patrones ocultos, como caídas que coinciden con saturación del sistema.
- Correlacionar eventos de Control‑M con logs y trazas en Datadog, si aplicable.
🧠 ¿Por qué no usar solo Control‑M?
Control‑M es muy potente para la orquestación y control del tiempo de ejecución, pero no tiene visibilidad detallada del sistema operativo, contenedores, redes, o servicios que están fuera del job.
Datadog, por otro lado, puede darte toda la telemetría de tu infraestructura, pero no conoce qué hace cada job.
🔗 Unir ambos te da lo mejor de los dos mundos: contexto de negocio + estado técnico real.
🧩 Ejemplo práctico: enviar eventos de job a Datadog
Supongamos que tienes un job importante llamado Proceso_ETL_1 que:
- Corre a las 2:00 AM cada día.
- A veces falla sin causa clara.
- Quieres saber si esos fallos coinciden con problemas de CPU o red.
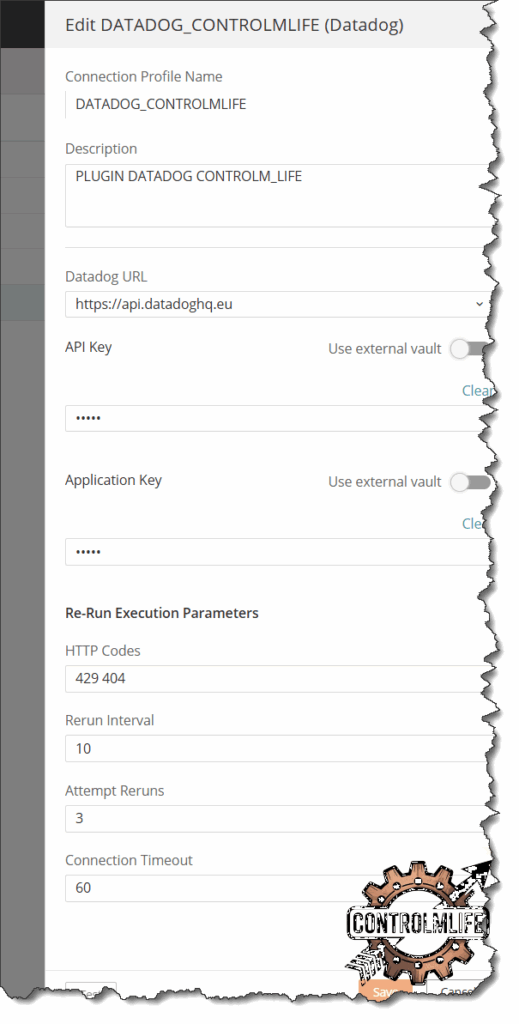
🛠️ Paso 1: Configura la conexión desde Control‑M a Datadog
- Asegúrate de tener el plugin «Control‑M for Datadog» instalado.
- Crea un perfil de conexión en Control‑M llamado
DATADOG_CONTROLMLIFEcon:- API Key de Datadog.
- Application Key.
- (Opcional) Proxy, si tu entorno lo requiere.
🛠️ Paso 2: Crea un job que envíe el evento a Datadog
Vamos a realizar una prueba con un job que falle y que de condicion a un job de tipo DatadogJob al final para que envie el evento
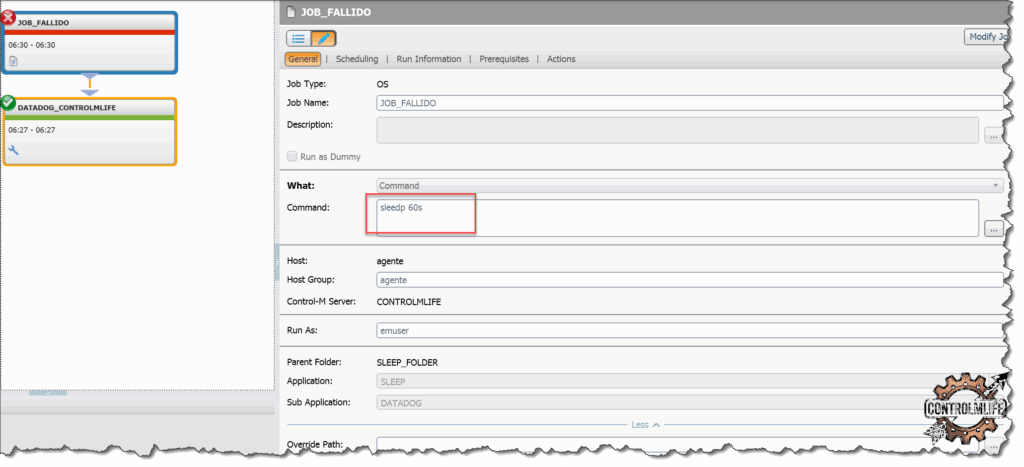
✅ Este evento aparecerá automáticamente en el timeline de Datadog, con todos sus metadatos, y se podrá filtrar, buscar y correlacionar con otras métricas.
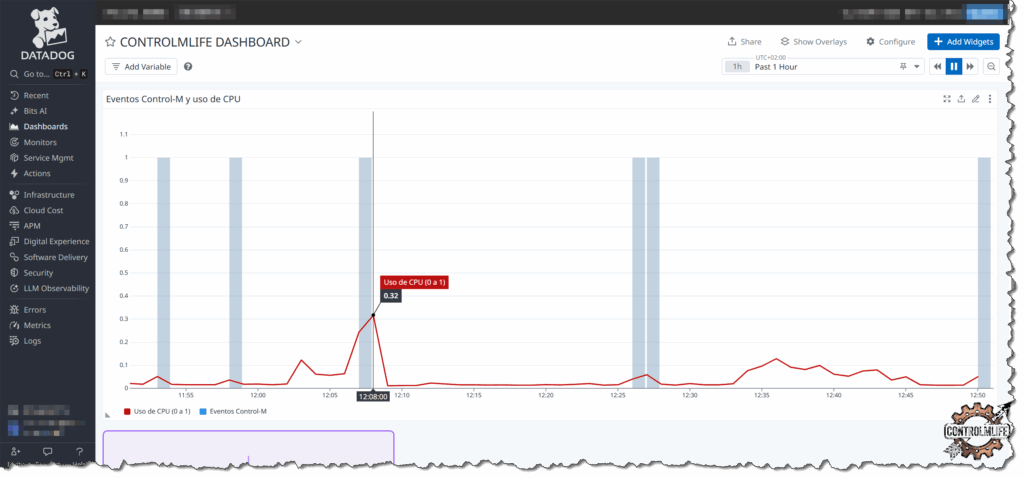
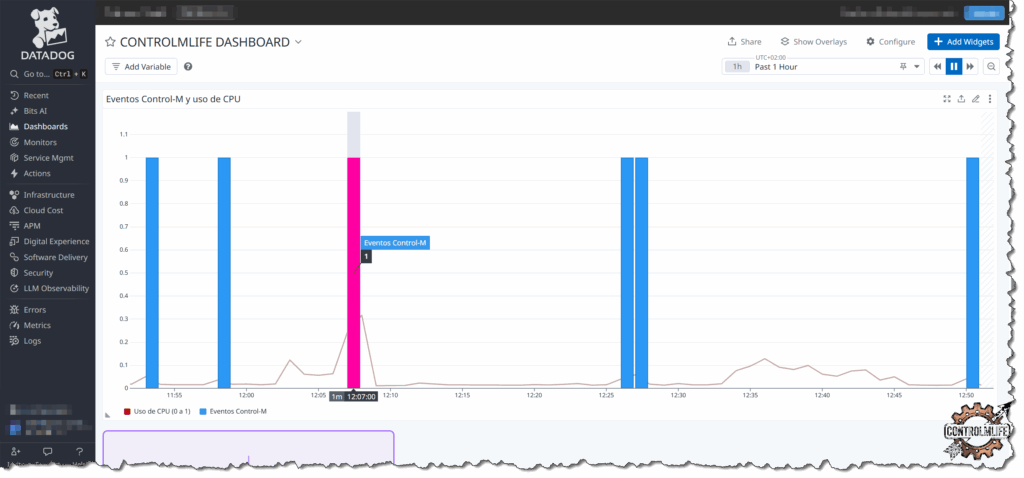
En las gráficas podemos observar que envía el evento del job y a su vez estamos monitorizando el uso de CPU pudiendo conseguir una relación entre ambas métricas.
Con este tipo de sinergia, conseguimos que cada herramienta enfocada en lo suyo se comunique con la otra para dar para dar una visión única y poderosa.